今天凌晨完成了自回归框架的初步搭建,到目前为止可以完整的进行模型的自回归生成了!如下图:
值得纪念的时刻。需要注意到的是:Greedy的sample策略会很容易引发一个大家现在已经不太关注的问题:注意力塌陷,即模型开始反复输出同一段话,无法进行任何有效的长文本输出。如果使用带有随机性的采样,这种情况就基本上不会发生了。这应该也是为什么Greedy在现在的模型采样方法里完全不采用。
而且可以大概看出,在短Prompt下,一个token生成的速度大约是~20tokens/sec。可以计算一下理论上其应该有的计算峰值:
$$ 理论最大速度 = 带宽 / 权重大小 = 288 GB/s / 3 GB ≈ 96 tokens/sec $$可以看出,naive实现相对于理想情况来说有效利用的比例并不高,只达到了大约21%的理论峰值。接下来我们的目标就是提升这个数字,并且提升OOM的阈限(利用主存甚至SSD)——先画个饼,提升到60%以上?
下面进行profiling,这在后面的开发当中将会作为baseline反复用到,用于和后面每一次优化进行比较。从16个token开始,每次增加16个token长度的seq_len,一直增加到4096。profiling的结果如下所示:
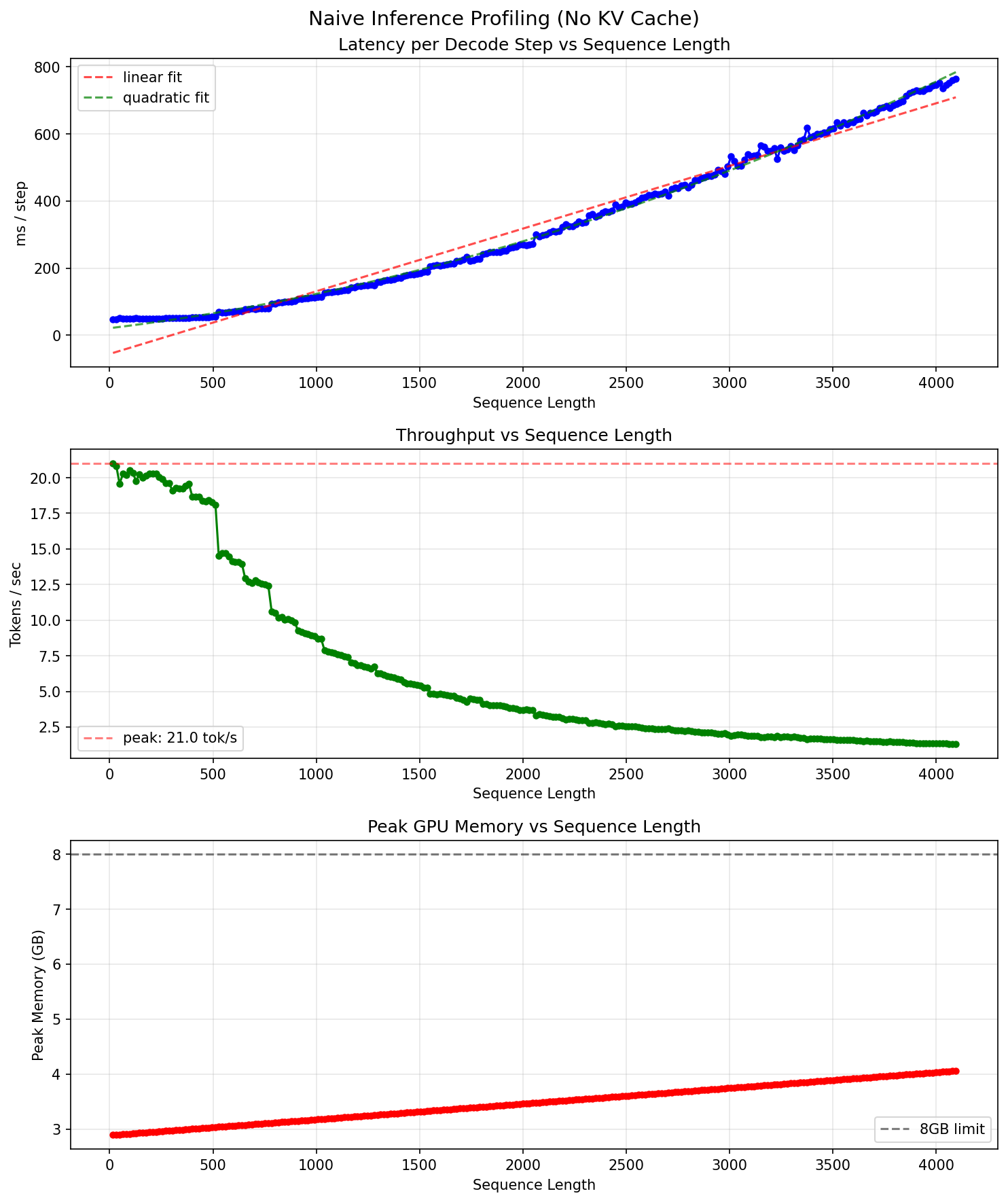
模式:Naive(无 KV Cache) 硬件:RTX 5070 Laptop 8GB
| Seq_len | ms/step | token/s |
|---|---|---|
| 16 | 47ms | 21.0 |
| 512 | 55ms | 18.2 |
| 1024 | 115ms | 8.7 |
| 2048 | 272ms | 3.7 |
| 4096 | 764ms | 1.3 |
可以明显的看到,在纯naive实现下,其主要分两段:常数段(生成速度几乎不变)和二次函数段(生成速度减慢的模式完美符合二次函数的增长)。常数段我认为应该主要是因为Latency以模型权重的反复加载为主,compute的时间几乎可以忽略不计,因此前向传播的Latency是固定的。而二次函数段就是经典的$O(N^2)$的注意力计算复杂度compute-bound导致的$O(N^2)$时间增长。此外特别值得注意的是,在大约seq_len=512~528的地方,出现了非常明显的性能阶跃式的下降。目前考虑的有pytorch的kernel调度的不同导致的,也有可能是L2cache溢出导致的换页导致的。究竟是什么导致的,后续也需要仔细研究。
总的来说,如果不使用KV cache的话,内存其实远远达不到OOM的程度(8+16GB的显存,仅仅用了4GB),token的生成速度就已经慢到无法接受了,更别提什么CUDA kernel的优化,都是于事无补。
此外,在测试的过程当中,第一次profiling的implementation在理论显存占用仅仅3.3GB不到的时候就OOM了。然而,反复计算理论显存也没找到为什么OOM。查询了之后才知道,原来pytorch不会自动释放显存,会把已经不再用到的、原先用过的显存块作为reserved模式保留在内部,哪怕马上就要OOM了也不会自动释放(确实这么离谱)。而每次因为序列是越来越长的,原先reserved的内存从未用上过,造成碎片单向增加而从不减少。这某种意义上来说和paged attention遇到的和解决的问题非常相似:只不过pytorch这个管理的更加低级。后面将会逐步实现naive的KV cache和Paged attention机制,随后再考虑kernel的优化。