今天实现了naive的KV cache,其效果之好确实令人震惊。vLLM根本没有提供不使用KV cache的推理方案,而且会按比例占据所有的显存,足可见KV cache在推理框架中的核心地位。先前的实验也证明了,如果不使用KV cache,推理速度很快就会下降到一个令人难以忍受的程度,从而不允许进行任何有实际意义的模型推理。
KV cache的思想
KV cahce的思想很简单,就是空间换时间。通过保存每一个先前token在经过各层(以qwen2.5-1.5B为例,就是28层)的attention层的时候,把它们的副产物:K和V保存下来。所以实际上,KVcache的shape大约是这样的(对一个请求来说):
$$ (Layer\_Index, K(0)/V(1), Seq\_Len, Num\_KV\_Heads, Head\_dim) $$在自回归过程中,一次前向传播,每经过一个TransformerBlock,前向传播的过程就把计算出的结果保存到一个大KV cache的相应位置上。Prefill的过程一次保存等同于input_prompt的token数量的KVcache,decoding过程则一次完整的前向传播增加一个。
虽然思想很简单,但工程实现相对来说没有那么简单。因为要对整个engine进行重构:原本不需要区分Prefill和Decoding,但现在需要了。进一步的说,这两者的需求根本不同:对于Prefill,由于方阵形状规整,算术强度是比较高的,因此Roofline模型更靠近compute bound那一端;而对于decoding来说几乎所有的时间都用来了进行模型权重的读取和KV cache的读取(虽然在我们这个例子当中效果并不显著),因此完全是memory bound的。这样,确实是从实践的角度感受了一下PD分离为什么最终会发生,这两者的计算模式是非常不一样的,尤其是当初始input的prompt很长的时候。
除此之外,一个非常容易错的点是:第一次写的时候很容易在每一层TransformerBlock里都把KVcache的Seq_len加一,但这样会造成同一个token的不同层的KVcache被存在了完全错位的地方。实际上,在layer_idx = max_layer - 1的时候把Seq_len加一就可以了。这是一个非常容易实现不对的地方,当时debug了半天。最后的代码长这样:
| |
希望看到的人能够绕过这个坑。
下面是使用了naive实现的KV cache之后,模型的decoding性能随着seq_len的变化的profiling图。
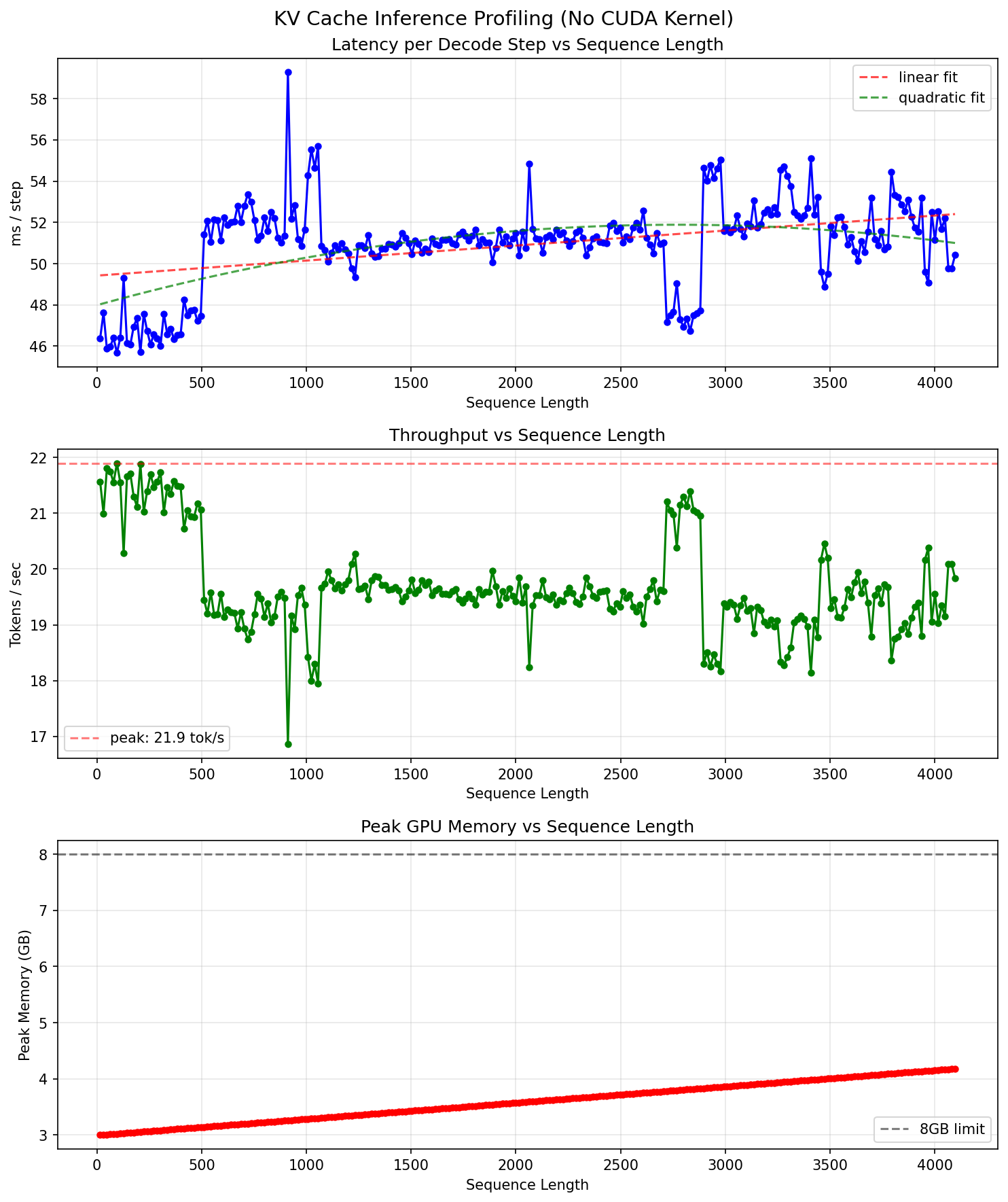
可以看到,对于1.5B这样的小模型(权重3GB)和<4096的seq_length长度来说,对于不同的sequence长度,单个token的推理时间几乎是一个常数,不会发生明显下降,和之前的naive实现的$O(N^2)$的曲线特征形成了非常明显的对比。这主要是因为权重读取相关的操作占据了绝大部分:这部分操作和seq_len是完全无关的,是$O(1)$的常数项。如果把length拉长,应该会看到后续的$O(N)$阶段,主要由KV cache本身的读取导致的带宽需求决定的Latency。不过由于我的卡(5070)的显存很小(8GB),在整个显存能够不OOM的范围内,几乎都不会发生这种情况就是了。
理论上来说,5070能够达到的推理速度大约是96tokens/s,目前的利用率仅仅只有22%左右。可以发现能够优化的空间还是相当大的,Kernel Fusion能够有相当的发挥空间。
一些思考
另外,今天和同学交流了一下未来的专精方向。算子开发本身似乎已经比较成熟了,通信库、高性能网络更值得做一些。确实如此,triton等等已经大大降低了开发难度,而且flashattn等各种算子融合和实现的库在pytorch里的生态也非常完善了。然而我的手上没有相关资源,只有单卡。但不论如何,也许应该考虑调整框架的开发方向?
目前的规划依然是要实现完整的KV cache。然而,prefix cache在目前的条件下,似乎没有个人开发者环境下有效评测的方法,这部分应该没有特别的高优先级的需求——可以往后推一推。
这样的话,目前的规划就是这样的:1、实现paged attention,2、进行Kernel Fusion的尝试和优化,3、实现单节点多卡推理,4、实现多节点多卡推理。