在完成Paged Attention的完整开发之后,下一步就是考虑提升性能了。
先来看benchmark。vllm在5070 Laptop上可以达到单Batch情况下,95 Tokens/s的Decoding速度。考虑到Decode阶段是绝对的Memory Bound,而5070 Laptop的理论内存带宽上限是382GB/s,这差不多相当于78%的GPU利用率。与此同时,在我的框架中进行相同的测试在Attention部分用自己写的Triton Kernel替换、进行了QKV Projection Fusion等比较重要的合并之后,性能虽然略微提升,但是在5070 Laptop上也仍然只有大约25~27 Tokens/s。即使是在进行了.compile()的default模式的编译之后,性能提升也最多只能达到大约31 Tokens/s。Profiling得到的性能情况如下图:
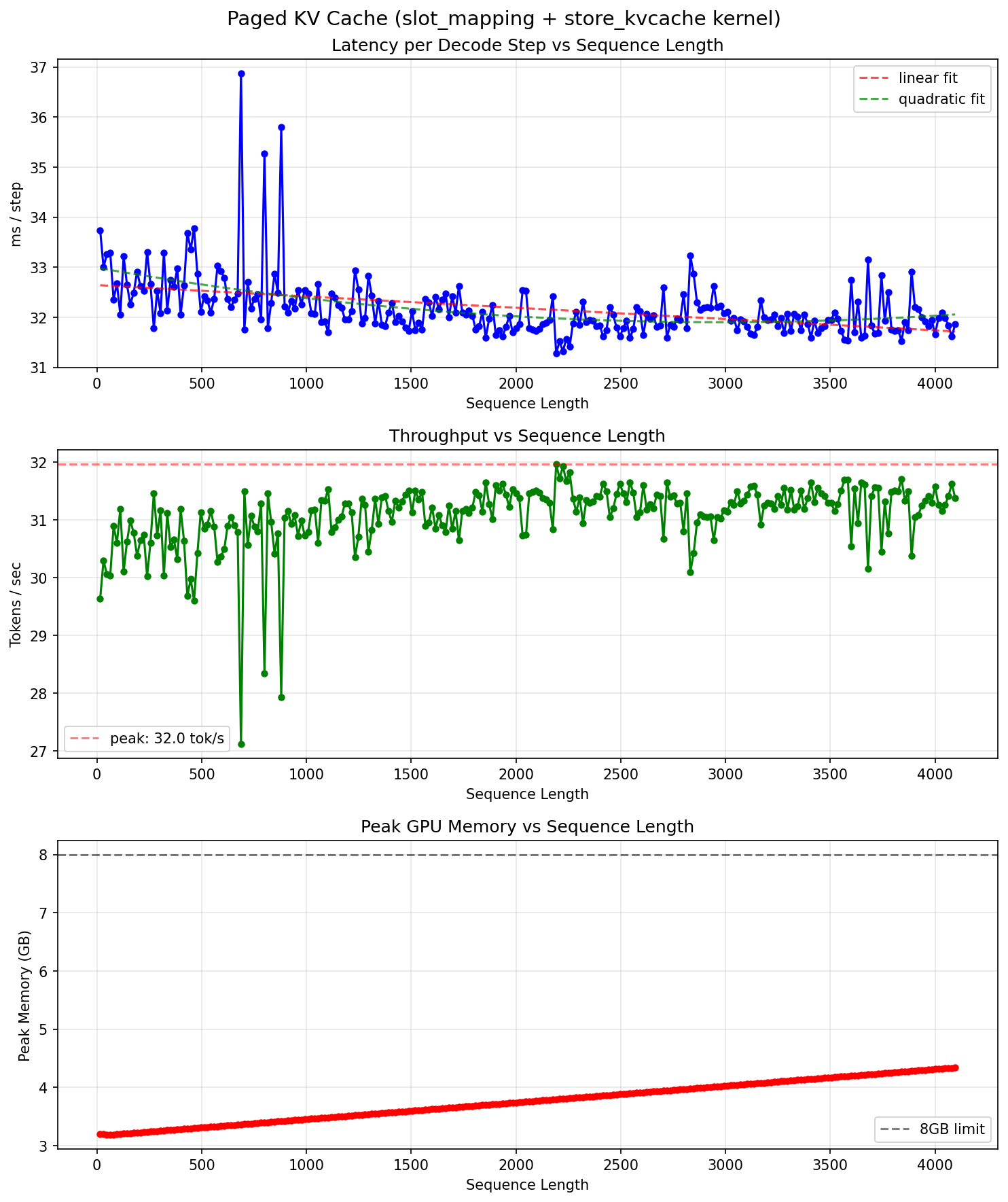
中间这4倍(对于eager模式)或者3倍(对于compile模式)的差距去哪里了?答案是,时间都被GPU-CPU的传输延迟、Python端的处理和CUDA API的Launch Kernel的开销吃掉了。这一点在WSL的环境下体现的尤其明显:对于WSL环境,一次CUDA API的调用就需要足足15微秒,比windows的原生环境和linux的原生环境都要长很多。而在一次模型的forward的过程中,至少会有大几百次(对于我在进行Profiling的时候使用的forward计算流,每个完整的Decoding步会产生851次cudaLaunchKernel的调用——仅仅调用本身的开销就消耗了13.5ms,而所有的GPU Kernel的实际开销也才11ms左右。因此,如果想要进行Decoding的性能的进一步优化,优化GPU Kernel的边际收益是很低的——继续减少一个本来已经占比不大的部分所产生的时间开销,其加速比永远不可能超过这个部分本来占据的比例本身。关键在于把更大的这一块优化好。
什么是CUDA Graph
CUDA Graph是一种可以减少CPU Launch Kernel的overhead开销的一种方法。为此,我们需要先了解CPU Launch Kernel的overhead开销是如何产生的。
我们知道,GPU在以前的很多场景下可不被称为GPU——它的另一个名字是加速器,或者说加速卡(accelerator)。这个说法有它自己的道理:GPU不会自己给自己发任务,它总是通过等待调用,被调用,返回结果的模式,帮助CPU进行它难以短时间完成的任务,也就是加速。这就需要CPU主动发放指令,这就是Launch Kernel。每一次kernel launch,CPU 都要经历一套流程:准备参数、调用 CUDA Driver API、把launch命令推入CUDA stream。GPU那边则从stream里取命令执行。关键点是这个过程是串行且逐条下发的:CPU发一条,GPU 收一条。即使 GPU 端的kernel执行极快(比如几微秒),CPU端每次launch也都是不可变的固定开销(WSL下~15μs),这部分是省不掉的。可以立刻得到的一条推论是,Kernel的数量越多,CUDA Graph的收益越大,反之则没有什么用。
CUDA Graph为什么能加速Decoding
大模型的推理Forward过程其实恰好就是许多个零碎的小Kernel组成的——而不是大家想象中的少数几个很大的Kernel。这一方面是因为layer堆叠的很深,另一方面是Attention、SwiGLU、RoPE等等的计算需求各不相同,完全无法进行完整的Fuse。在eager模式下,这样的控制流需要CPU亲自介入反复发放——而这个发放的时间无法完全overlap,很多Kernel在GPU上工作的时间甚至远短于CPU的launch开销,更别提在这个过程中,可能还夹杂了Paged Attention的实现的非最优实现引发的CPU侧反复的Tensor创建、内存分配等等行为。如果不实现CUDA Graph,可能很多人都没有意识到自己在中间有哪些动态拷贝拉低了性能。因此,CUDA Graph的实现过程产生的副产品其实比CUDA Graph本身还要更多一些。
对于大模型本身来说,CUDA Graph造成的直接收益则是如下几条:
第一,CPU端从N次launch变成了1次,直接砍掉了N-1次的driver调用开销;
第二,GPU端由于提前知道了完整的执行计划,调度器可以做更激进的优化(比如提前准备下一个kernel的资源);
第三,消除了CPU-GPU之间反复同步的 round-trip(不一定是Kernel本身造成的,正如我之前所说,可能有很多不经意之间的非最优实现)。
CUDA Graph的技术原理
一句话总结的话,它的本质其实是录制和重放。这有点类似于宏录制和宏重放的思想:把一套线性的、无条件分支发散的操作流程固定下来,然后在输入数据不同的情况下反复重做。这样,一整个过程本身只需要启动一次,后面GPU自己会知道怎么做。
CUDA Graph做的事情就是:把一系列kernel launch的指令序列,或者说launch的顺序、拓扑依赖关系,全部提前录制(capture)下来,形成一个有向无环图(DAG)。图中的节点是各个kernel(以及memcpy、memset等操作),边表示它们之间的依赖关系。录制完成后,这整张图可以作为一个整体一次性提交给 GPU 执行。CPU 端只需要一次 launch 调用(cudaGraphLaunch),GPU 端就会按照图中定义好的顺序和依赖关系依次执行所有节点。
如何使用CUDA Graph
这东西的使用其实很简单,不过它的限制也很大。它的使用方法真的就是字面意义上的“录制和重放”——先在开启录制的完整的跑一遍,然后调用replay相关的操作。从api角度来解释的话,流程如下:
cudaStreamBeginCapture → 正常调用各种 kernel → cudaStreamEndCapture → 得到一个 cudaGraph_t → cudaGraphInstantiate 生成可执行的 cudaGraphExec_t → 之后每次只需 cudaGraphLaunch即可。
具体而言,在pytorch的实现当中,可以参考这段代码的流程:
| |
CUDA Graph的使用限制
所有“录制和重放”应该有的限制它都有。总结一条的话,它必须是线性的、静态的。
第一,所有的指针不能变动。换句话说,你不能使用任何“新内存分配”、“新张量创建”,所有这些操作本质上都是新分配内存空间、返回新指针,而CUDA Graph只接受静态的不变化的指针,那么当然也就只指向同一块空间、同一个Tensor。在不同的调用当中,能够做到的就是向固定的static的input里覆写不同的内容,以实现不同循环的不同输出。这也是为什么block_table在vllm实现里是定长的。
第二,控制流必须固定。 换句话说,录制时走过的分支就是回放时会走的分支,不能有data-dependent的 if/else。这意味着如果你的forward里有根据输入动态选择不同kernel路径的逻辑(比如根据seq_len是否超过某个阈值来决定用哪个attention实现),这些在 graph 内部是做不到的。所有的条件判断必须提到 graph 外面,在 CPU 端决定好之后选择对应的 graph 来 launch。
第三,kernel的launch配置(grid size、block size)和调用序列必须完全一致。 就像前面说的那样,一次录制记录下了851次kernel launch,回放时就真的只会严格按相同的顺序launch这851个kernel,grid/block参数也完全不变(作为静态变量,本质上,和前面的指针是一样的)。这直接意味着tensor shape不能变——因为绝大多数kernel的grid配置是根据tensor shape算出来的。对LLM inference来说,这一点的影响很大:decode阶段每一步kv cache的有效长度都在 +1,如果attention kernel的grid size依赖于seq_len,那严格来说每一步都需要不同的 graph。实际工程中的处理方式通常是用padding或者按seq_len区间预录制多张 graph。
第四,不能包含CPU-GPU同步操作。 比如cudaMemcpy(同步版本)、cudaDeviceSynchronize、或者任何会阻塞CPU等待GPU结果的调用,都不能出现在capture的过程中。因为capture阶段这些操作并不会真正执行,录进去会导致语义错误。同样,任何需要读回 GPU 数据到CPU再做决策的逻辑(比如early stopping,CPU介入检查EOS token)也必须移到graph外部。GPU必须表现的像CPU根本不存在一样来进行重放。此外,每一步检查EOS token这种操作会造成严重的性能影响(因为要进行同步和拷贝),一般是按照预定的长度,生成很多个(比如100个token),然后转交给CPU,检查有没有出现EOS token,是在哪里出现的,然后再进行进一步处理和截断。
下面这条是Claude老师补充的:
第五,不能在graph内部使用CUDA的动态并行(dynamic parallelism)或者跨stream的复杂同步。 Stream capture对stream的使用有严格约束,虽然支持在capture期间fork出子stream来表达并行性,但不能随意使用event做跨graph的同步。这部分我还没有研究过,不是很懂,先记下来。
总结一下的话,CUDA Graph本质上是把一段GPU执行流"快照"下来、机械性的、死板的重放。任何运行时才能确定的东西,包括新的内存地址、动态的控制流、变化的shape、CPU端的同步和决策等等,都和它不兼容,能改变的只有固定地址里的数据内容。
CUDA Graph的加速效果
非常好。直接上图⬇️:
这个直接达到了大约92%的vllm性能。后面通过进一步的Triton-Kernel的接入和fusion,应该完全可以做到93~95token/s,彻底追平vllm。
一点思考
在做这部分工作的时候,也在想Vera CPU这种东西会不会让Graph变得更不那么必要?
“Vera CPU 通过 NVLink-C2C 和 Rubin GPU 直接互联,提供 1.8 TB/s 的 coherent 带宽,构建了 CPU 和 GPU 之间的统一地址空间。”
也许以后。这就得等Rubin真的能摸到再说了。