今天的主要工作是接入了更多的Triton Kernel,进一步完善代码和进行性能优化,并且把Decode的性能拉到了可以接受的程度。后面还有一篇阶段性的总结,主要讲一讲遇到的令我比较有印象的错误、呈现的形式和最终解决的方法。稍后更新。
小小的炫耀一下:
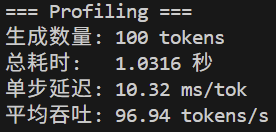
之前提到,vllm的性能是95.0tokens/s左右。已经和vllm完全持平甚至略微超过了!engine的适配和测试也已经整理完成,接下来就是准备重新开始学习、调研多卡的实现方法、设计多卡的扩展实现路线图了。
其他基于Triton Kernel的性能优化
除了之前的博客提到过的几个重要的Kernel或者不用Kernel的矩阵乘法合并优化,在完成 PagedAttention 的核心实现之后,nsys profiling 的数据显示GPU计算时间仍有优化空间。GEMM和GEMV在这个过程中已经占据了大约80%的GPU时间,这部分受限于硬件带宽,难以突破。但剩余的20%里藏着几个可以用Triton消除的低效模式:显存的重复读写和不必要的中间变量分配。通过剩下的零碎Kernel优化,仍然可以实现将近10%的性能提升。
1. Fused RoPE & Paged KV Cache Store (显存读写合并)
这是收益最大的一次融合,解决的是一个隐蔽的"显存回旋镖"问题。
在之前直接随手写的naive实现里,apply_rope会产生一系列临时tensor:先slice切出前后两半,再neg取负,最后cat拼回去。每一个操作都是一次独立的GPU kernel,意味着中间结果要反复写入显存再读出来。更糟糕的是,RoPE算完的K会先落入连续显存,然后store_kvcache再把它读一遍,按slot_mapping的地址写入分散的物理Cache块。同一份K的数据在没有然后额外处理需求的情况下被搬运了两次,造成冗余。
融合后的kernel把这个流程压缩成一次:从全局显存读入Q、K、V、cos、sin,在寄存器里完成RoPE旋转计算,全程不进行临时变量分配。计算完成后,Q写回连续显存供后续Attention使用;而寄存器里的K_rot和V则直接通过slot_mapping提供的物理地址,一步写入非连续的Paged Cache块,不再经过任何中间缓冲。
GQA的处理是这个kernel需要特别注意的一个设计细节。以框架适配的模型Qwen2.5-1.5B为例,Q有12个头,K和V只有2个头,Grid设计时需要让每个program明确知道自己处理的是Q头还是KV头,以及对应的KV头索引是哪个。通过kv_head_idx = head_idx // (N_HEAD // N_KV_HEAD)的映射,kernel内部自然地处理了这个不对齐问题,调用方不需要任何额外操作。
这个收益大约有5Tokens/s,也就是说足足5%。
2. Fused SwiGLU (MLP 层激活函数与乘法融合)
SwiGLU 是相对好发现和动机更直接的一个Kernel fusion操作,不过相对来说收益没有前面那个那么大。原始的F.silu(gate) * up`需要进行是三次显存IO:读gate、算SiLU、写临时结果;读临时结果和 up、做逐元素乘法、写输出。实际上这三步在计算上完全可以流水完成,没有任何数据依赖要求它们分开。
Triton kernel把gate和up同时加载到寄存器,在寄存器内连续执行Sigmoid、gate与Sigmoid结果的乘法(SiLU),以及与up的逐元素乘法,最后一次性写回全局显存。三次读写变成一次,访存带宽需求降低到原来的三分之一。
实现上把3D tensor(batch×seq×hidden)展平成1D视角来划分Block,这样kernel对任意的batch size和seq_len都能够天然兼容,不需要针对不同输入形状做特殊处理。
这个收益大约有2Tokens/s。
3. Triton RMSNorm (pow mean add sqrt和mul的算子融合)
这个算子fusion的目的是,把RMSNorm自身的多个零碎的PyTorch算子合并成一个Triton kernel。
原始的PyTorch实现 x.pow(2).mean(-1).add(eps).rsqrt().mul(x).mul(weight) 实际上在GPU端会拆成5~6个独立的elementwise kernel,pow一次、mean(reduction)一次、add一次、rsqrt一次,最后还有两次mul。每个kernel都有独立的 launch 开销,中间结果要落入全局显存再被下一个 kernel 读出来。对于28层×2个Norm=56次/步来说,这些launch虽然单次很小,累积起来也有可观的数量。
Triton kernel的做法很直接:每行(即每个token的hidden_size维度)分配一个program,一次性把整行1536个元素加载到寄存器,在寄存器内完成平方求和、除以N、加eps、rsqrt、乘权重的全部计算,最后一次写回。6个kernel变成1个,中间没有任何全局显存的临时读写。
这里要特别注意一个踩了的坑:必须用BLOCK_SIZE取hidden_size的下一个2的幂次(1536→2048),用mask屏蔽超出部分。这个实现实际上不是可选的二世必须的,来源于Triton对tl.arange的要求。具体来说,Triton要求tl.arange产生的长度必须是编译期常量且为2的幂。如果不是这样,会直接出错,在这里记录一下以提醒后来人。
此外,计算全程在float32下进行以避免bfloat16的精度溢出,写回时再转换为输入的原始dtype。
这个收益大约有2~3Tokens/s。
4. Fused Add Norm 失败
Fused Add Norm的融合是计划中的第4个优化,目标是在前面第三个的基础上更进一步,把残差加法和归一化也合并成一个kernel,从两次显存读写变成一次。实现上用Triton在Block内部完成方差计算和归一化,逻辑并不复杂。
动机很直接:在TransformerBlock里,残差连接和RMSNorm是紧挨着的两步操作。原始流程是先做x = x + attn_out(一次全局显存读写),再把结果送入RMSNorm(又一次读写:pow → mean → rsqrt → mul)。同一份数据在没有任何计算上的阻隔的情况下被搬运了两次。Triton kernel 的设计思路是把这两步压缩进一个 kernel:在寄存器里完成x + residual之后,就地计算方差、rsqrt 和缩放,x被in-place更新为加完残差的值,返回的是归一化后的结果,全程只读一次、写两次(一次更新 x,一次写 normed_out)。
但实际上测试下来不仅没有增加性能还减少了。是负收益,降低了大约2~3Tokens/s。尝试问问AI,给出的其中一种解释如下:
PyTorch 原生的 elementwise kernel 对这种小规模操作已经做了充分优化,走的是高度特化的 launch 路径;而 Triton kernel 有自己的一套 launch 机制,对于这种计算量极小、一个 warp 就能处理完的操作,Triton launch 本身的固定开销反而比省下来的显存带宽还大。更具体地说,在 Qwen2.5-1.5B 的 decode 阶段,hidden_size 只有 1536,batch_size 为 1,整个 RMSNorm 的输入只有 1536 个 float16 元素(3KB),连 L2 cache 都装得下,根本不存在"显存回旋镖"的问题——数据在 cache 里就地复用了,多读一次的代价几乎为零。
不过,我个人认为这应该就是launch overhead的问题。就是不知道pytorch的原生实现到底为什么能够更快,后台又对不同size做了哪些优化?因为按理来说,elementwise的操作应该完全没有什么特别的优化空间才对。别说Triton了,可能用CUDA几小时写一个naive版本也能达到接近可达上限的性能。那到底是为什么?这个问题可能需要后面有时间再对pytorch做进一步的了解,现在先记录下来🤔。
这个收益大约是-2~-3Tokens/s,确认为负优化后已回退。保留了Triton版本和相关注释没有删除,作为参考。
把所有这些全部加上,性能基本上就能够和vllm一样了。当然,这是单Batch的情况,多Batch由于Scheduler的调度策略非常不同,测试的意义也不是很大。