这次的工作量主要在于实现了ZeRO-1和ZeRO-2。老实说,这部分确实下了很多功夫:因为ZeRO是一个需要分段实现,但是抽象概念上有许多共通之处的,相当大的核心feature组件。如果仅仅是硬编码进去,后续的开发就会不断的制造屎山,侵入性的修改相同地方的代码,导致不可维护性(Pico-vLLM的PD分离的时候我就是这么干的.jpg)。在查询了资料(而且在使用ai反复进行框架验证)之后,最终采取了一个完整的插入性组件系统的设计。它的核心思想是“接管”,即利用预制的系统内接口的预留、默认的No-Op占位符的设计、功能性组件和工厂类四者的协调,实现可扩展的整个ZeRO系统。下面讲讲我认为有价值的细节。
ZeRO-1的细节
即使在Python也要坚持类型安全
虽然没什么特别高深的理论,但在这里真的特别值得强调一下。虽然Python是一个弱类型语言,但在一个框架当中,坚持类型安全的写法是极其、极其、极其重要的!它可不只是你面前的红色波浪线是多还是少的问题,真的不要低估它带来的作用。第一,它可以识别极多的低级错误,作为最基础的提示工具,帮助开发者回忆和建立正确的上下文,其功能性不亚于自动补全工具。第二,即使没有错误,它也可以极大的降低心智负担,从而允许我们以更低的心智劳动成本建立对框架的整体认知、回忆(或者了解)先前开发者的设计意图,避免破坏现有的设计模式。在Pico-vLLM当中,由于急着开发,很多地方并没有这么做、凭借记忆和直觉写代码,从而导致后面再次要修改代码的时候,经常出现无意间破坏了先前设计的核心不变量和默契的情况,从而极大的增加了维护工作量。切记:如果能不加入none,坚决不要加入;不管有没有如果,每个关键参数的签名都要完整写出。defensive有时候是好的,有时候是让代码变得不可维护。
这种态度的代价不会在写代码时显现——会在改代码时显现。可以这样举例子:
- 看到
Tensor(不带| None),就知道"原设计者认为这里永远不该是 None" - 想改成
Tensor | None时,会先停下来想"为什么原来不允许 None,现在为什么需要" - 这个停下来想的瞬间就是类型注解的全部价值
ShardingStrategy 作为一等抽象
往代码里加ZeRO-1时,大家的第一反应可能是"找到 mp_manager.step,把里面的all-reduce改成reduce-scatter"。但这种"修改实现"的路径意味着每加一种sharding模式都要改step代码,前面写得好好的抽象就全完蛋了。众所周知,所有地方都做的很好,一个地方漏了,复杂度就会回到这个最差组件的水平上。这同样是不可持续的反模式。
实际上,ZeRO横跨了precision和sync两个职责。它既决定master怎么分片(属于precision),又决定grad怎么同步(属于sync)。放在哪个模块都会产生很糟糕的耦合。因此,它应该是一个独立的横切概念,这样就自然导向一个决策,即新增一个sharding模块,作为插件设计,采用“接管功能”的思想去设计。
它的基本抽象如下:ShardingStrategy 协议有四个方法 make_master / reduce_grads / gather_weights / post_step。它们刚好对应ZeRO 在训练流程中需要介入的四个时机点。NoShard和ZeRO-1是同一个协议的不同实现,trainer 看到的接口完全一致,只不过前者基本都是No-Op而已,不执行实际功能。当不启用功能的时候,工厂函数。
master 是 1D 分片而不是按 shape 切
这是用ai查资料的时候学会的。我最初的简单思路是:weight是[V, H],在dim 0上进行切分,切给dp个rank,每rank 持有[V/dp, H]。这么做其实也能够保证正确性,但在未来可能有性能问题。在追求高性能的实现当中,相应的参数其实是压平+拼接去做的:把所有master参数当成一个巨大的一维向量,然后在这个一维向量上切。此外,如果把不同层、不同参数拼接在一起,就可以几乎完全消除切分的不均匀性质,实现最大程度的不同节点间参数ZeRO-1风格的均匀分配。虽然现在我们不会去实现这个bucket策略,但依然值得提前留下这样一个位置。
ZeRO 启用时 GradSync 退化为 NoOp
也是一个抽象层面的有趣选择。ZeRO-1启用后,原来负责 DP all-reduce的GradientSynchronizer的功能被完全接管了,。因为 strategy.reduce_grads 内部已经做了reduce_scatter。但与此同时,trainer依然还在调grad_sync.sync_gradients()这个函数,它是正常执行的。如果在开发Pico-vLLM的时候,我大概会把整个组件删掉,破坏性的重写整个框架(然后把前面所有的测试脚本全部作废)。不过现在我有经验了嘛!这个时候,前面学习的工厂类模式就起作用了。何不返回一个No-Op,再通过恰当的工厂类设计让不同的配置返回不同的GradientSynchronizer呢?事实证明是可以做到的。通过直接调用先前预留的No-Op,很轻易的就在不破坏任何核心代码的情况下,完成了修改。
当然,接口稳定的代价是少量"无意义"的调用。对于每一个插件可能要用到的地方,即使只有字面意义上的1个其他类型插件用到了,也得实现工厂类函数、No-Op、先前流程的的fallback,还有固定的预留接口。这可能被称为丑陋,但它的意义在于让其他地方可以制造少得多的丑陋。换句话说,用这种代价换来的是trainer代码对底层变化的免疫力。No-Op在很多时候是必要的,在强调可扩展性和可持续。
ZeRO-2的细节
即使是Python的Protocol也可以承担多重角色,比多重继承更轻
注意了,这可不是严格意义上的C++的多重继承。它只是行为上的“形似多重继承”。Python Protocol满足是行为上的:一个类不需要 inherit任何Protocol,只要它有Protocol要求的方法签名,类型检查器就认它满足。这是**"behaves-as"**关系,类型层面的鸭子类型。
以我们的strategy为例:
class ZeRO2Strategy: # 没有继承任何 Protocol
# ShardingStrategy 需要的方法:
def make_master(self, ...): ...
def reduce_grads(self, ...): ...
def gather_weights(self, ...): ...
def post_step(self): ...
# GradientSynchronizer 需要的方法:
def sync_gradients(self): ...
def no_sync(self): ...
def state_dict(self): ...
def load_state_dict(self, sd): ...
这个class就能同时作为 ShardingStrategy 和 GradientSynchronizer 来使用!这一点如果用好了,会有既减少复杂度,又保证类型安全的奇效。它作为插件是非常合适的。
不过也要小心它的代价:因为它并不是全或无关系,缺失的方法会被以默认路径补全。在不严格模式下,类型检查器不会提醒我们。此外,IDE跳转可能不友好,因为大多数时候跳转到的是Protocol本身,没法再跳转到具体实现了。因此,最好把Protocol和它的实现,它们的文件组织在尽可能临近的位置上。
注意事项
这次的debug花了很多时间,但大部分原因是自己写测试脚本的时候不小心导致的一个极度隐蔽的测试脚本的内存测量污染bug。具体情况如下:
现象:跑测试发现ZeRO-2显存比ZeRO-1还大,"偶尔正常但无法复现"。
排查bug的过程如下:
- 第一反应是 strategy 实现有 bug,hook 没真清掉 compute.grad
- 加 print 验证 hook 触发了、_grad_shards 填充了、compute.grad 是 None
- 然后怀疑 copy_grads_to_master 的 zeros_like 问题,但发现 local_grads 不是 None
- 最后意识到问题不在 ZeRO-2 实现,而在测试脚本本身
根因:测试脚本在 baseline → ZeRO-1 之间做了 del + empty_cache + barrier,但ZeRO-1 → ZeRO-2之间漏了。这本来是因为ZeRO-1本就在计算部分的最后面,原本没有必要进行del、empty_cache和barrier。在加入ZeRO-2之后,它却变得有必要了。这就导致 ZeRO-2 的 max_memory_allocated 测量是从一个被ZeRO-1残留污染的基线开始的,导致很多莫名其妙而且不确定性的问题。
这确实是一个值得记录下来的问题。测量代码本身可能就是 bug 源头,尤其是分布式 + GPU + Python GC 这种非确定性多重叠加的场景。怀疑实现之前先怀疑测量。此外,"偶尔能复现正常结果"是个强信号。这是因为确定性bug不会偶尔正确,所以问题很可能在不确定性的地方(GC 时机、caching allocator),对排查很有帮助。
当然,一劳永逸的解决此类问题的办法是多写循环。循环的每次执行内容是相同的,自然就没有这样的问题了。希望这对于读者有所帮助。
测试结果
直接看图:
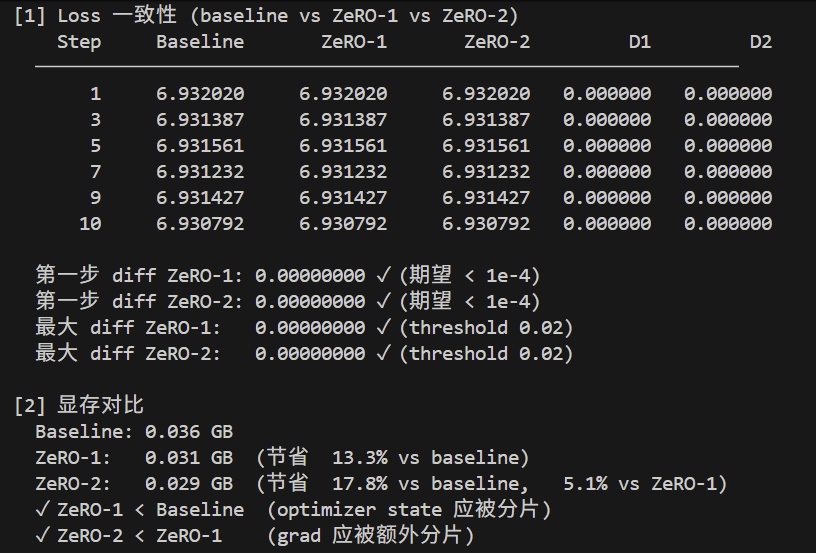
虽然ai建议我设一个阈值,不过实测下来发现其实是可以bit级别对齐的!也就是说,良好的实现确实不应该损失可察觉的精度。
此外值得注意的是,ZeRO-1跑通时的显存节省数字是13.3%,ZeRO-2则是17.8%。这个数字看上去小的可怜,完全不像论文标题里写"可以省4倍内存"那么dramatic。不过,如果有心的读者愿意计算一下的话,会发现这个节省量恰好精确等于理论上通过参数量计算出来的对于显存的节省量(节省了5.1MB。理论上,模型总的参数+梯度+优化器状态需要6.83MB来存储),也就是说实现并没有错误。
这个比例刚刚看到的时候吓了一跳,还以为是我实现错了,有哪里没有正确的实现导致走了原路径。算了半天显存占用量才发现,不是节省的东西少了,而是额外的东西多了,而这些东西占的比例还不低。这个结果出现的原因主要是测试用的是个tiny model(256 hidden、2 层。小的可怕!),optimizer state和grad在总显存里的占比本来就小,再加上nccl等等工具需要的buffer、杂七杂八的overhead占用,最后的结果就是激活和buffer占了大头。
而额外多出来的就是所谓的激活和buffer占用的内存,它们无法被节省从而拉低了比例。模型放大到 7B 之后这套节省比例就会非常显著了。顺带一提,这也是后面实现“选择性激活检查点”技术的驱动力之一:分片存储来节约显存能够达到的水平是有上限的,而且越是往后边际收益越低,代价却越大(ZeRO-2和-3的需要分段通信就是典型的例子,通算重叠不仅很难做,而且大多数时候无法完全掩盖。尤其在 ZeRO-3 上,通信在forward/backward都要每层做,forward前要all-gather weight、forward后要reshard,通信链路上的拓扑、网卡数量、PCIe 带宽等等各种各样想得到想不到的问题都会成为瓶颈。也因此,许多工程团队在实践当中都只使用ZeRO-1级别的分片,以避免性能浪费)。当这部分已经做到足够好的时候,检查点存储带来的短暂显存峰值就显得不那么可接受了。这就催生了选择性激活检查点(Selective Activation Checkpointing,SAC,也可以叫选择性激活重计算)策略的工程需求和实现。
至于如何实现呢?大家可以思考一下。