今天的工作量实现的是选择性激活检查点(SAC,Selective Activation Checkpointing)。这个组件相当简单,因为Pytorch已经。因此这篇日志会相对来说较短,主要着重于介绍它的概念、机制,以及实现过程中遇到的值得记录的bug,以供读者或者其他的后来人参考,避免踩同样的坑。
SAC是什么
SAC是一种降低训练中内存占用峰值的技术,代价是增加反向传播当中的计算量。它的具体原理是,每隔一段“距离”,保存一个可以进行前向传播的中间激活值,抛弃这个距离中的两个端点之间的所有其他值。当反向传播开始/越过一个检查点的末尾的时候,我们如果遇到的接下来的反向传播路径当中没有现成的中间激活值,就从最近的一个检查点重新向前计算,重新铺好这段反向传播需要的中间激活值路径。
SAC的理论最优情形
假设我们的模型参数由连续均值的$L$层构成,而检查点每隔$N$层设置一个。此时,可以直接计算出,显存的峰值占用分为两个部分:一个是$1/N$个的检查点层,一个是$N$个的正在进行反向传播的段落,两者加起来就是$N+1/N$。这个式子的最小值点大家应该都熟悉,初中数学嘛。因此,如果想要显存占用最小化的话,理论上来说,$N=\sqrt L$是能够让显存峰值占用最小的点。
SAC的主流实践
当然,工程上通常并不会这么做,因为这个理论模型和现实差的很远,而且并不一定符合我们的MFU最大化的目标——SAC过于稀疏将会导致密集的重计算(recomputation),从而带来额外的计算负担,拖慢训练。SAC的主流实践一般以层为最大粒度:每层保留结构位置相同的Checkpoint,具体保留哪些则由具体策略决定。
Pytorch提供的现有机制
SAC的实现意外的很简单,因为它在实现上基本就是直接复用Pytorch现有的基础设施组件。具体而言,它使用类似以下的代码进行SAC的设置和激活:
| |
就是这么简单,核心代码其实就是利用_torch_checkpoint进行一次前向传播时候的调用包装。当然,用户也可以自定义这个warpper,但大多数时候利用基础设施当中的现有组件就已经完全够用了。
值得注意的Bug和问题
SAC的bug
在这个过程中,遇到了一个特别棘手的问题:Pytorch反复报错。当第一次前向传播的时候很正常,接下来反向传播回去的时候却报错,而报错信息显示多了两个不知道是什么的tensor,整个ckpt的tensor数量从38个变成了40个,对不上。这个bug的排查过程非常艰难,几乎花了我3~4个小时的时间,才定位和理解了问题发生的具体原理。
在排查之后发现,发现这其实不是我们本身的代码实现错误,而是Pytorch后端调用的自动切换导致的。实际上,这就是HuggingFace著名的 use_cache + gradient checkpointing 互斥问题。
它的具体的引起原因来源于LlamaModel的默认设置,config.use_cache=True,也即自动保存和管理KV cache,以加速前向传播。第一次forward时,cache为空,因此调用了 _scaled_dot_product_flash_attention(因为它满足FlashAttention的shape要求)。 recompute时,cache已经被填充,因此K/V的seq长度翻倍,不再是空tensor,因此数量就对不上,同时不满足FlashAttention的causal mask约束,dispatcher fallback到math backend,因此具体的后端实现也发生了变化。这两个因素加起来,导致报错。
它其实原本是有一个内置防御机制,避免这个问题的,类似这样的形式:
| |
但只有调用 model.gradient_checkpointing_enable() 或者把 model.gradient_checkpointing = True 设上时这条防御才生效。它的判据是 self.gradient_checkpointing 这个flag,而不是探测调用栈里有没有checkpoint,因此失效。这确实是一个值得记录下来的教训,在部分采用现有基础设施来构建框架的时候,一定要注意这种细节问题,即内部耦合的组件的边界恰好被切分开的时候,所暴露出的协调失效问题。
SAC能带来多少收益
来看图:
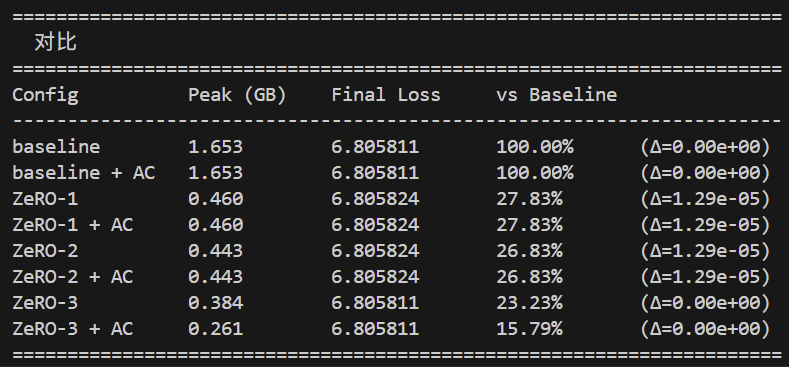
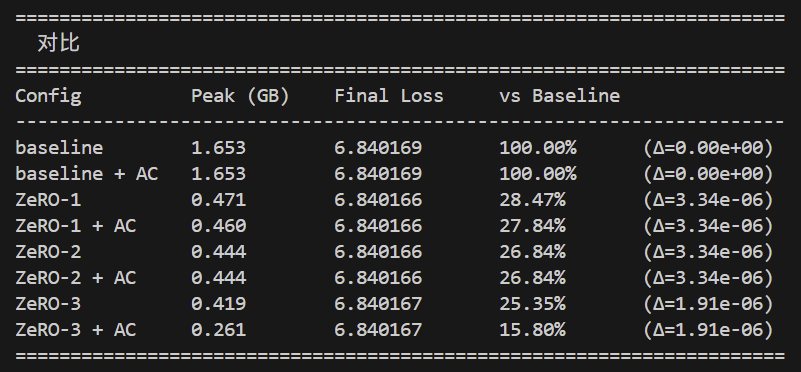
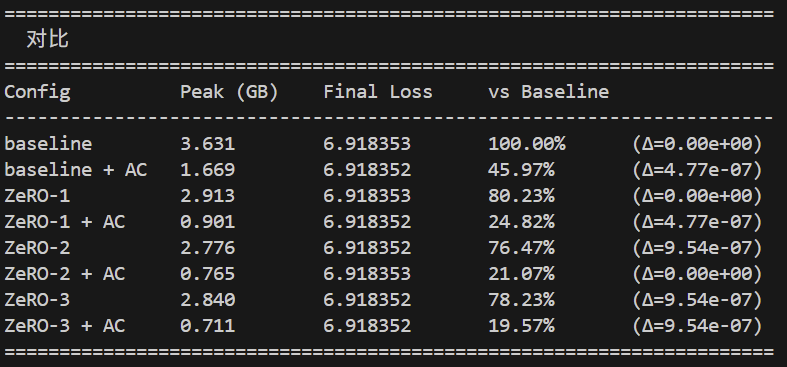
亲爱的读者们,如果你们无论怎么测试,得到的都是类似前者的第一张图的结果,你们会不会质疑自己的代码实现有问题呢?至少我是会的:因为内存占用是bit-exact的完全没有变化,看上去更像是SAC根本没有正确加载和起效,而不是它在机制上是真的没有用。我反复排查了很久是不是实现有问题(包括在最后走投无路开始折磨AI),最后发现其实代码根本没什么问题,确实就是它没有压低显存峰值。通过反复的测试参数,将seq_len从测试用toy-model的16改成32和1024,就得到了第二张图和第三张图内的数据结果,而第三张图看上去就正常多了。
这其实说明一件事:SAC对于seq_len不是非常长的情况,能够产生的收益非常有限。但又能够看到,ZeRO-3对于seq_len非常长的情况,收益同样也有限,甚至还不如ZeRO-2。这说明两者其实应该同时使用,而且在DP较多、PP较少的组合上收益更明显。而且,在通常的toy-model的参数范围内,收益整体的量级并不如传统的博客、资料当中描述的那么明显。这很可能是因为SAC出现的时间早于Flash Attention导致的。后者虽然在scope上是一个对于计算局部性的著名Kernel优化,但无意当中抢走了Selective Activation Checkpointing的饭碗,直接让SAC按标准注意力实现的优化收益标准彻底无效了。
实际上,在Flash Attention被发明之后,SAC的核心收益就变化了:因为Flash Attention的计算流根本不物化那个巨大的完整的注意力矩阵,而SAC最初出现的主要目的就是为了规避这个巨大矩阵带来的显存占用问题,导致它从一个几乎是不做到最好就完全不能进行大模型训练的核心技术,退居为一个只要做的合理就能产生合理收益的技术。它节省的现在主要是超长序列带来的中间激活值的膨胀问题,而不再是一个万能万灵的通用手段。
如果SAC特别慢,可能发生了什么
另一个问题是在测试的时候发现SAC特别慢,到了难以忍受的地步。这个其实是个bug,其来源让人好笑,是调试的时候加上的ActivationCheckpointWrapper.forward 中debug设置导致的:
| |
从机制原理上来说,这个torch.utils.checkpoint.checkpoint(debug=True) 的设置会激活一个 TorchDispatchMode, 给原始forward装上Python级dispatch。这是为了使得每个op能够经过Python一遍,以完整记录元数据,进一步为了recompute时检测不一致,能够给出方便调试的友好错误。这原本是为了。然而,改完了之后却忘了改回来,随后彻底忘记了这件事,搞得我在之后做集成测试的时候奇慢无比,浪费了很多时间(起码多花了一个多小时,多花了五六十块钱,呜呜呜)。
如果大家遇到类似表现的问题,记得排查这个设置有没有改对。